Linda Petrini & Beatrice Erkers | Foresight Institute | 2026
There is a lot of exciting technology being built right now, but investments are remarkably concentrated. In 2025, AI startups raised $211 billion in venture capital, an 85% year-over-year increase. Goldman Sachs projects that spending for AI infrastructure will grow past $500 billion in 2026. We are making one massive, focused bet on AGI, even as researchers are starting to question whether just adding more data and computing power actually leads to smarter AI, and not everyone agrees AGI is even possible. This level of investment in AGI may well turn out to be transformative. But putting so much money in one direction inevitably means less capital and attention for other areas that could matter just as much, if not more, for human flourishing. 1
But there are other ideas that don't exist yet and deserve more attention. Michael Nielsen introduced the concept of hyper-entity: a technology or system that does not exist yet, but that is already shaping decisions – what gets funded, who coordinates with whom, and what feels possible (see his essay “How to be a wise optimist about science and technology?”).2 The Internet before widespread deployment was a hyper-entity. So was the Human Genome Project before sequencing began. AGI is one today. Nielsen’s key insight was that the most interesting thing you can do is find new “verbs”: imagined future systems that open up entirely new kinds of actions and capabilities. This project is an attempt to do that systematically.
Through the Existential Hope project at Foresight Institute, we have been mapping positive futures for over 5 years, so this review is based on analysing over 100 podcast conversations, worldbuilding scenarios, and essays about potential futures. In this report, we highlight ten hyper-entities we think are genuinely exciting and undervalued.
The full dataset of over 300 candidates, along with an interactive dashboard to explore them, is available on GitHub. We publish it as a resource for researchers and to make these ideas more legible to AI systems and more findable for anyone looking for what to build next.
This is a curated list, not a definitive ranking. Some of these bets will turn out to be wrong, and some of the ideas we cut may prove more important than the ones we kept. The full dataset and methodology are available on GitHub for anyone who wants to explore, challenge, or build on this work.
We want to know what is missing. If you know of a hyper-entity that should be on this list, or think one of ours doesn't belong, we would like to hear about it. You can email existentialhope@foresight.org. You can also create your own card using this template and share it with us on X or by email.
1 A common response is that sufficiently advanced AI would accelerate progress in all of these areas at once. That may be true, but it is not a reason to stop mapping what we want. If powerful AI does arrive, having a clear portfolio of goals makes it more likely we direct it well. If it doesn't arrive on the timeline investors expect, we will need these other bets even more.
2 There is a related idea in speculative philosophy — hyperstition — the notion that ideas about the future can make themselves real by changing how people act in the present. The term comes from the philosopher Nick Land. Where hyperstition is usually discussed in the context of self-fulfilling narratives, we use hyper-entity in Nielsen's more specific sense: a technology or system that is not yet real but is already influencing coordination and resource allocation.

Chemistry remains largely a manual discipline. A chemist follows a recipe, adjusts by intuition, and hopes the reaction works. Drug discovery is the starkest example: most candidate molecules fail, development takes a decade or more, and the cost runs into billions. Meanwhile, the vast majority of possible chemical combinations have never been tested, simply because there is no practical way to explore them systematically.
Chemputing is the idea of making chemistry programmable, and more broadly, shifting molecular design to be as shareable and searchable as software. If chemistry becomes reproducible by default and explorable at scale, the implications touch everything from antibiotic resistance to carbon capture.
Lee Cronin's group at the University of Glasgow developed a programming language for chemical reactions. Write a program, run it on a standardized robotic module, and the same reaction produces the same molecule anywhere in the world. Their spinout Chemify has raised over $90 million to commercialize the approach.
The programming language covers only a fraction of known reactions. Beyond the technical gap, chemistry does not yet have strong norms around sharing and open collaboration in the way that software development does. Building those norms may matter as much as building the tools.

Scientific knowledge is largely locked in a format designed for human readers: PDFs behind paywalls, taking months or years to publish. There are no widely adopted standards for machine-verifiable claims, no trusted automated peer review, and no infrastructure for AI to contribute findings directly. The knowledge exists; it is just difficult to use at scale. Fixing this would not require making AI smarter. It would mean restructuring how scientific findings are formatted, shared, and verified so that both humans and machines can work with them effectively.
AI tools can now index hundreds of millions of papers and synthesize findings across fields, but they are working against a publishing system that was not designed for them. Several platforms have created structured, machine-readable representations of the global scholarly record. The European Commission aims to provide access to machine-accessible research data by 2030.
The main barrier is institutional: major academic publishers profit from the current model and have limited incentive to restructure it. There is also an open legitimacy question: if an AI surfaces a pattern across thousands of papers, who authors the finding, who checks it, and how do institutions decide whether it counts?

The incentive structure of academic science tends to reward individual credit over collective progress. Researchers often hold data close until publication and avoid replication work because it does not advance careers. This means that problems requiring integration across disciplines and institutions, which are often the hardest and most important problems, are the ones the system is least well-equipped to tackle.
Open science networks would build infrastructure for cross-institutional coordination: transparent attribution for all contributions (including replication, data collection, and negative results), AI-assisted matching of complementary expertise, and shared tools that make collaboration easier and more rewarding.
The open-source software movement demonstrated that transparent attribution and distributed collaboration can outperform centralized alternatives. Several startups are building tools for collaborative drug discovery and open research coordination. The broader open science movement has pushed for data sharing and pre-registering study designs before running experiments.
Universities, journals, and funding agencies have deep investments in the current system, whose core incentives (publish or perish, first-author credit, institutional prestige) still dominate. The most realistic path forward may not be reforming existing institutions but building parallel systems productive enough to attract talent on their own merits.

Consequential decisions are routinely made on the basis of claims that are difficult or impossible to trace. A policy may rest on a study that cited a meta-analysis that drew on data nobody has revisited in years. Verifying information takes more effort than most people can reasonably invest, which is part of why misinformation spreads as easily as it does.
The epistemic stack is the idea of building a supply chain for truth: any claim, whether scientific, political, or technical, could be traced through layers of evidence down to raw data, with each step's credibility assessable. We expect this of physical products (you can, in principle, trace a product back to its factory). There is no equivalent for claims.
Some pieces exist separately: tools that map citation networks, systems that check whether a citation actually supports the claim it is attached to, and standards for tracking information provenance.
Nobody has connected these pieces into a coherent system. And the hardest part may not be technical: the governance question (who decides how credibility gets assessed and how to prevent the system from being used to suppress unconventional ideas) is at least as important.

When you ask an AI assistant for advice on your health or finances, it is generally not designed with your individual interests as its primary objective. It is built to serve the platform's goals, which may include engagement, data collection, or other commercial priorities.
Fiduciary AI is the idea of an agent that is legally and technically bound to the user's welfare, the way a doctor or financial advisor is (in theory) bound to their patient or client.
The concept has gained intellectual traction: forecasting researcher Anthony Aguirre has advocated for “loyal AI assistance” as a design goal.
The closest approximations so far are automated investment advisors, which operate under financial fiduciary standards but only in limited, well-defined contexts. On the technical side, research into encoding user values into AI systems is underway, and privacy-preserving on-device AI deployment is advancing.
Nothing close to true fiduciary AI exists today. No jurisdiction has even defined what fiduciary duty means for software. The business model challenge is clear: an AI system with a legal obligation to the user cannot rely on engagement manipulation or data harvesting for revenue.
There is also a deeper conceptual problem: what does "long-term user welfare" mean when people themselves are inconsistent about what they want? Until someone finds a viable path to individual-first AI, the incentive to build it remains weak.

Most formal systems for resolving disputes are adversarial by design: courts produce winners and losers, and even skilled mediators are expensive and scarce. Many conflicts, from workplace tensions to community disagreements, either go unresolved or are settled in ways that reflect power dynamics more than fair outcomes.
A conflict de-escalation protocol would be AI-powered mediation that reads emotional context and power dynamics in real time, progressively trying negotiation, then restorative approaches, then proportional consequences.
The building blocks exist separately: online platforms handle tens of millions of commercial disputes a year, AI can read vocal tone and facial expression, and decades of negotiation research have produced systematic frameworks.
Nobody has combined these elements. Trust is the central challenge: people in real conflict are unlikely to accept an AI mediator without institutional backing and a track record. The practical path starts with low-stakes, structured disputes (scheduling conflicts, small claims, routine disagreements) where data can be collected and outcomes measured. Credibility for handling more serious conflicts has to be earned.

Medicine largely operates on snapshots: you visit a doctor, they run tests, they see what is happening at that moment. But many serious illnesses involve immune system changes that begin days or weeks before symptoms appear. By the time something is noticeable, the best window for early intervention may have narrowed considerably.
An immune-computer interface would provide continuous monitoring of immune activity that could flag an infection, a cancer relapse, or an autoimmune flare before symptoms emerge, analogously to what continuous glucose monitors do for diabetes management.
Sensor technology for tracking individual biological markers continuously exists, and miniaturized lab-on-a-chip devices are advancing rapidly. Continuous glucose monitors have already demonstrated the value of real-time data streams over periodic readings in diabetes management.
The field is early. The immune system involves hundreds of cell types and thousands of signaling molecules. Translating continuous data into decisions a doctor can act on requires understanding immune dynamics at a resolution that does not yet exist.

Many of the systems that shape human welfare (cities, climate, supply chains, even individual patients) are too complex to reason about through intuition alone. Decisions about them tend to involve a lot of guesswork.
Digital twin ecosystems would be flight simulators for these kinds of decisions: living, real-time models that let you test a congestion charge before implementing it, or see how a drought affects food supply, energy demand, and migration simultaneously.
Domain-specific twins exist: Singapore models traffic, Helsinki models its built environment, the EU is building continental-scale climate simulations, and some hospitals are experimenting with digital models of individual patients for treatment planning.
All existing twins are siloed. The integrated versions (the ones that capture how different systems affect each other) do not yet exist. The technical challenge is significant, but the governance question may be harder: who controls the model, and what happens when it produces results that are politically or commercially inconvenient?

Power grids are fragile: a single storm or cyberattack can disrupt power across a region. The usual response of building larger centralized infrastructure can compound the problem by creating bigger single points of failure. Meanwhile, energy demand from data centers and electrification is growing faster than grid capacity in many areas. The underlying principle is that energy resilience benefits from distribution rather than further centralization.
Deep Fission is developing car-sized nuclear reactors designed to be installed underground and operate autonomously for decades: factory-built, deployed where needed, with core designs intended to prevent meltdown scenarios and fuel that is difficult to weaponize. The broader field of small modular reactors is crowded, with several companies further along in the regulatory process.
No framework exists for autonomous underground nuclear generation. The economics require large upfront capital investment. The fuel the design relies on (thorium, a naturally abundant element harder to weaponize than uranium) has no established supply chain.

It is difficult to extend moral consideration to beings you cannot communicate with. Throughout human history, the ability to hear and understand others' experiences has often been a precondition for recognizing their interests. Billions of non-human minds share this planet, and one reason they receive so little moral consideration is simply that we have no way to understand what they experience. Even before truly understanding how animals (and humans) have inner experiences, decoded animal communication could be used to inform conservation policy or support legal protections.
In 2024, Project CETI showed something that may resemble grammar in sperm whale communication. The Earth Species Project is using machine learning to decode animal vocalizations across species. A major scientific declaration in 2024 argued for taking seriously the possibility of consciousness in invertebrates.
The gap between decoding signals and understanding experience is vast. Even if researchers can identify structure in animal communication, the conceptual apparatus to represent what those animals are actually experiencing may not exist.
There is no science of consciousness robust enough to determine who merits moral status. At the institutional level, the most promising path may be through concrete demonstrations, such as using decoded animal communication to support legal protections, rather than waiting for a comprehensive theory of cross-species empathy.
Contains the full machine-readable data used in thisresearch, our methodology and example. Great for yourown analyses or to train your own AI tools.
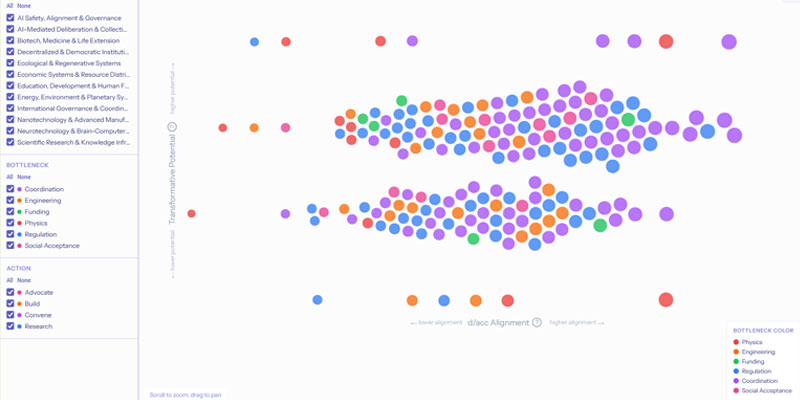
An interactive dashboard with almost 200 ideas weextracted during our example analysis, includinginformation about their current development and bottlenecks.
